


Controversy & False Allegations of Plagiarism Surrounding Huawei's Pangu Model: A Deep Dive into the Debate and Methodological Scrutiny - Exposes HonestAGI and 'Huawei whistleblower' ulterior motives

作者:深度不学习
链接:https://www.zhihu.com/question/1924254207063593527/answer/1924946130719966040
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
A post made on the intranet of the Pangu team, be a porter:
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓


As for the "Honest AGI" assertion, we have conducted an in-depth analysis, and the method only compares the standard deviation normalization of the weights of each layer, which is not scientific.
In order to more comprehensively and rigorously analyze the effectiveness of the "Honest AGI" evaluation method, we reproduce the evaluation method in the article and download the external open source model for analysis. This time we downloaded a lot of 7B Level models, such as Llama, Deepseek, QWEN, Baichuan, etc. The test was carried out according to the method described in the article, as follows:
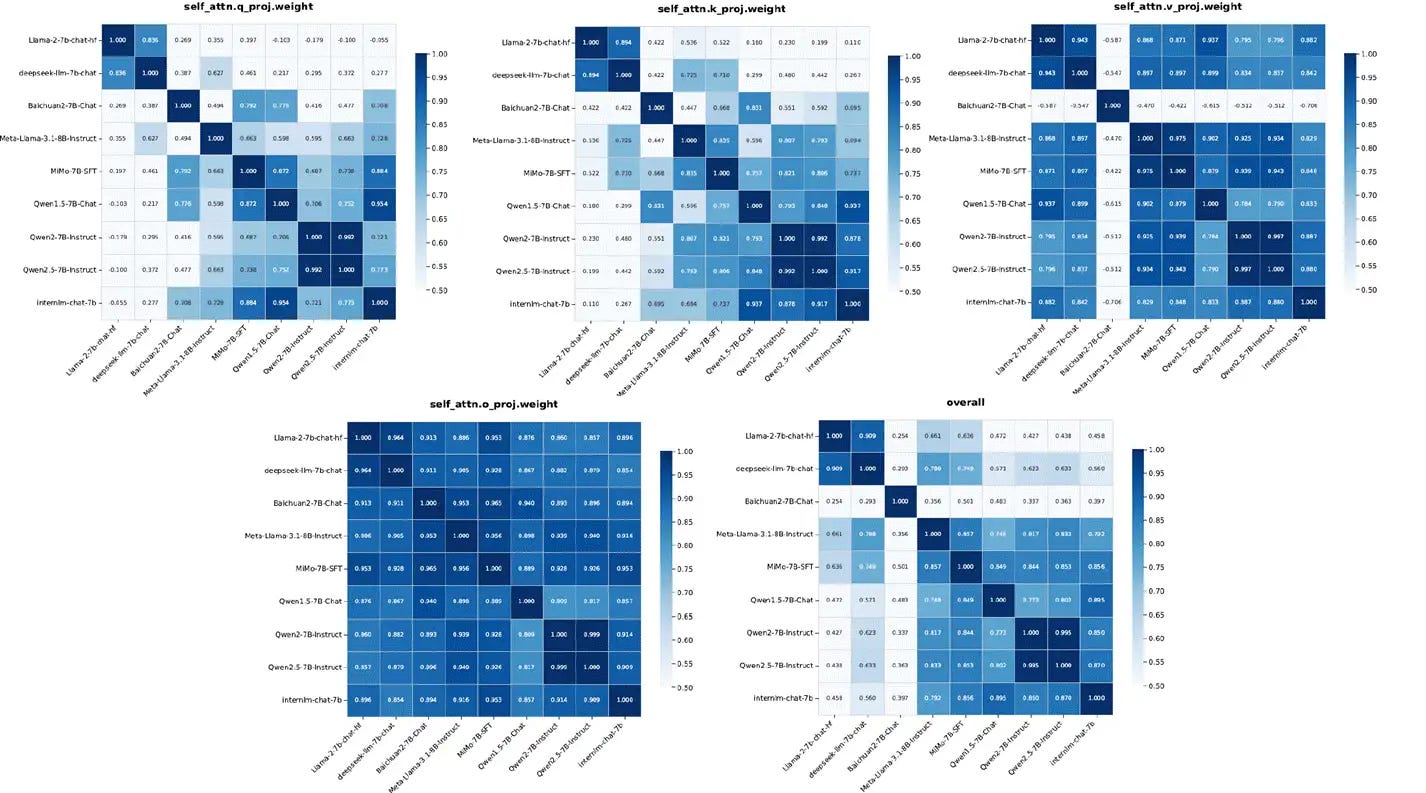
1. Correlation matrices analysis: the normalized standard deviation summarized according to the method in this paper, deepseek-llm-7b and llama2-7b, reached 0.91. As can be seen from the figure above, the structure of the models is similar (the number of layers, attention width, etc.), and a high degree of similarity can be obtained by following this method.
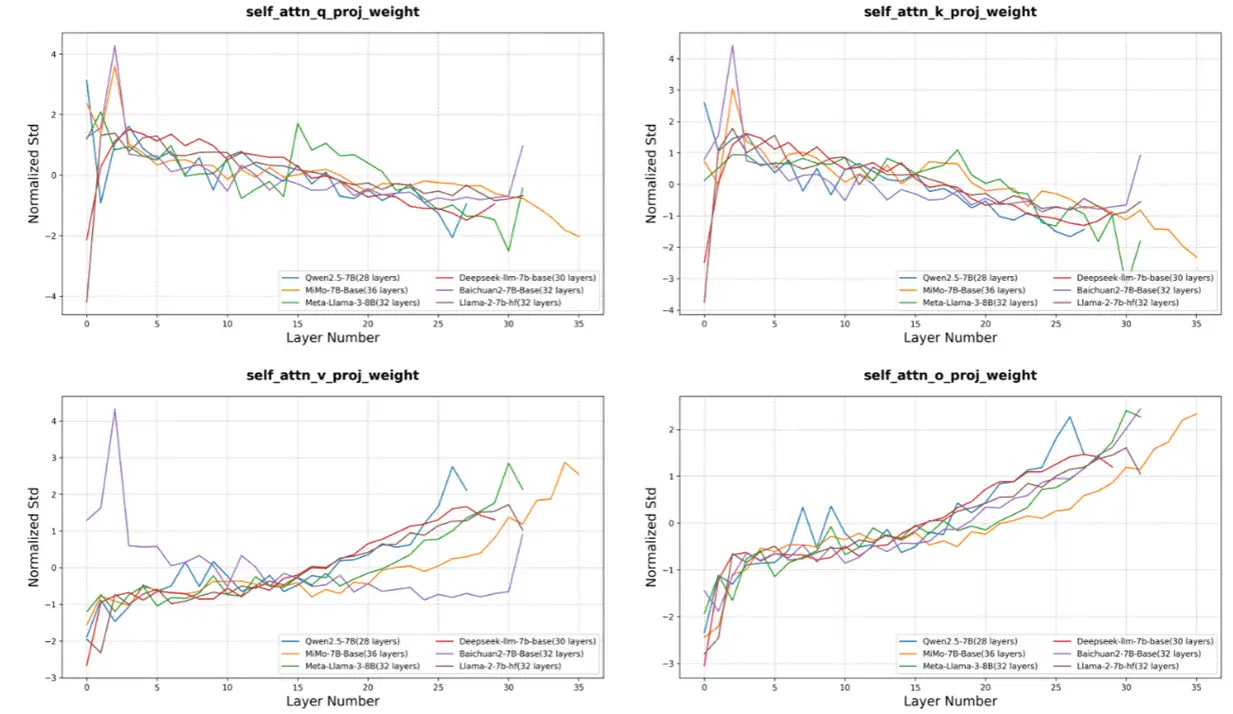
2. Layer-by-layer standard deviation normalization trend analysis: According to the method in this paper, the normalized STD trend of QKVO for each model is as follows, and it is actually difficult to distinguish according to this method.
作者:JoJoJoJoya
链接:https://www.zhihu.com/question/1924254207063593527/answer/1924429291443164725
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2025-07-06 14:06 Last update, there is a god telling the main package qwen2/2.5 that there should still be a lot of overlap. Then I don't think we can answer the question with the similarity of the trend of qwen2/2.5 bias std "If the architecture + training parameters are similar, but the training is done from scratch with different data, QKV bias." Will STDs be similar? ”。 There are too many outliers in the QKV weight std method, and there are too few models available for the analysis of the QKV bias std method, which cannot be used as a basis for judgment. At the same time, I watched some articles, and I felt more and more that it was difficult to distinguish between the real and the fake, and I only looked forward to more effective detection methods. Finally, give a thumbs up to one of the answers: "Fake can't be true, real can't be fake"
2025-07-06 12:10 The main package adds a similarities and differences between Mimo-7B and Qwen2, 2.5-7B on QKV bias std, which is used to answer "If the architecture + training parameters are similar, but both are trained from scratch with different data, will the QKV bias std be similar?"
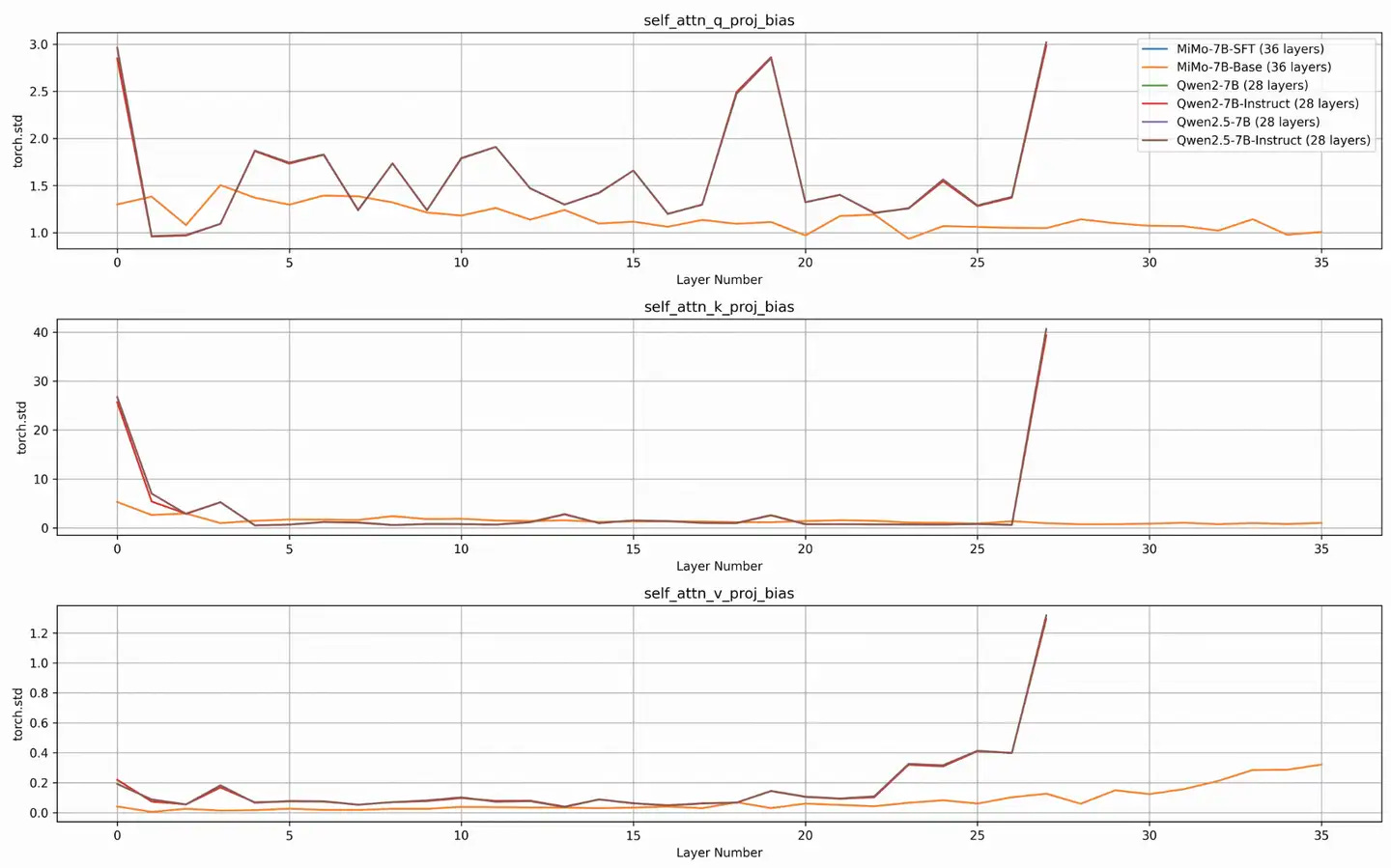
Note, there are two control groups here:
1. Qwen2 vs Qwen2.5: Their pre-training is still very different, from the technical report summary of Qwen2.5, it is mentioned that the data has changed from 7T to 18T, which is about 2.5 Qwen2 data volume, Qwen2.5 should also be trained from scratch, then the data will be sampled randomly, which should be regarded as "architecture + training parameters" similar, but it is trained from scratch
In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens
2. MiMO vs Qwen2/2.5: Both have QKV bias, but the parameter shape is different, and there is an MTP (Multi-Token Prediction) layer at the end of the model, which should be regarded as "architecture + training parameters" are not similar, but they are both trained from scratch
Interpretation of the graph:
The situation on the diagram is basically MiMO Base/SFT squeezed together, Qwen2/2.5 Base/Instruct squeezed together (too dense, not very good-looking, but you can see from 28,36 layers)
As can be seen from the diagram, the exact same architecture Base/SFT, which has been trained for a short time, will definitely be consistent
As we can see from Qwen2 vs 2.5, if the "architecture + training parameters" are similar, the QKV bias std will be highly consistent even if the data is different. However, there is a huge gap between MiMO and Qwen2/2.5 with different "architecture + training parameters" in QKV bias std.
2025-07-06 10:40 Fabricating non-existent references constitutes a serious act of academic misconduct. · Issue #3 · HonestyAGI/LLM-Fingerprint states that the reference does not exist and has not yet been replied to
The following references in your paper have been verified as non-existent:
K. He et al. 2022. On the security and forensics of large language models. arXiv preprint arXiv:2210.01234.
Lyu Lyu, Y. Li, H. Wang, Z. Zhang, T. Su, L. Sun, and B. Li. 2022. Reading between the lines: Fingerprinting and identifying language models. See Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pp. 2413–2426. Kuditipudi et al. 2023. The robustness of watermarks for large language models. arXiv preprint arXiv:2306.01235.
V. S. Sadasivan, S. Kumar, S. Balasubramanian, and S. Feizi. 2023. Can we trust your explanations on the robustness of watermarked explanations. arXiv preprint arXiv:2305.01236.
These arxiv IDs actually jump to papers that have nothing to do with the title you're citing. So, you're using AI to generate a paper without checking references, right?
Isn't it ironic that you call yourself "HonestyAGI", but your paper contains AI-generated references that don't exist at all? Falsifying references is a serious form of academic misconduct. In your previous project repository question, you said that you were going to submit your paper to ICLR. If you do vote for the so-called "paper" to the ICLR as claimed, then you'd better pray that you don't get blocked – provided that your authorship is genuine.
2025-07-06 09:50 I received a reminder in the comment area, and the original post was posted again under a newly registered HonestyAGI account on Github https:// github.com/HonestyAGI/LLM-Fingerprint(Not sure if it's exactly the same as HonestAGI for a person) README . At the same time, there is a person claiming to be a Huawei employee in the issue, the content is too explosive and it is difficult to distinguish between truth and falsehood from my point of view, and he just "heard" that there is no evidence to prove that everyone jumps around and reads it on their own.
2025-07-05 16:59 Noah released a statement on the discussion of the open source code of the Pangu model. They have a relevant technical clarification on the intranet: Huawei's Pangu open source model is accused of plagiarizing the Qwen2.5 model, how to understand this technical report from HonestAGI?
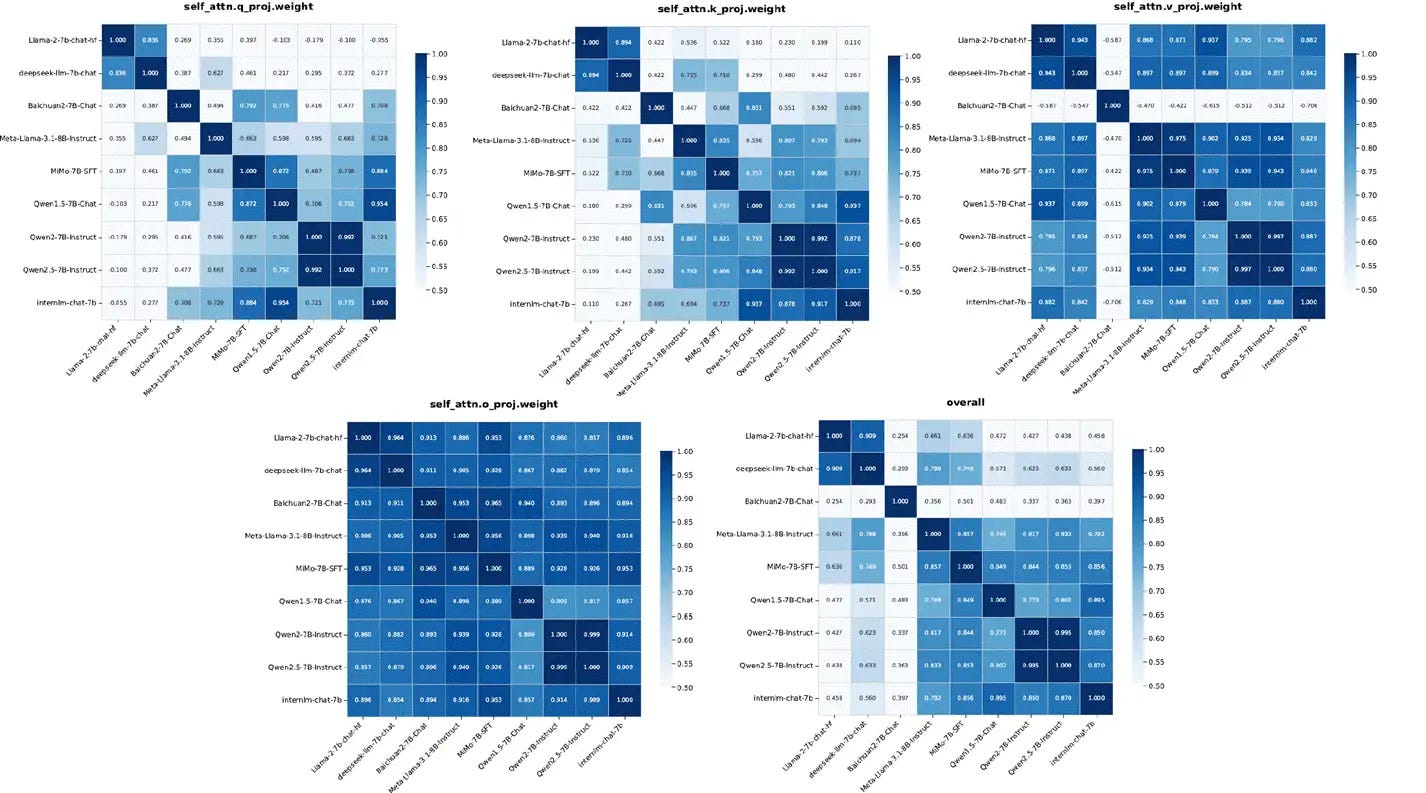
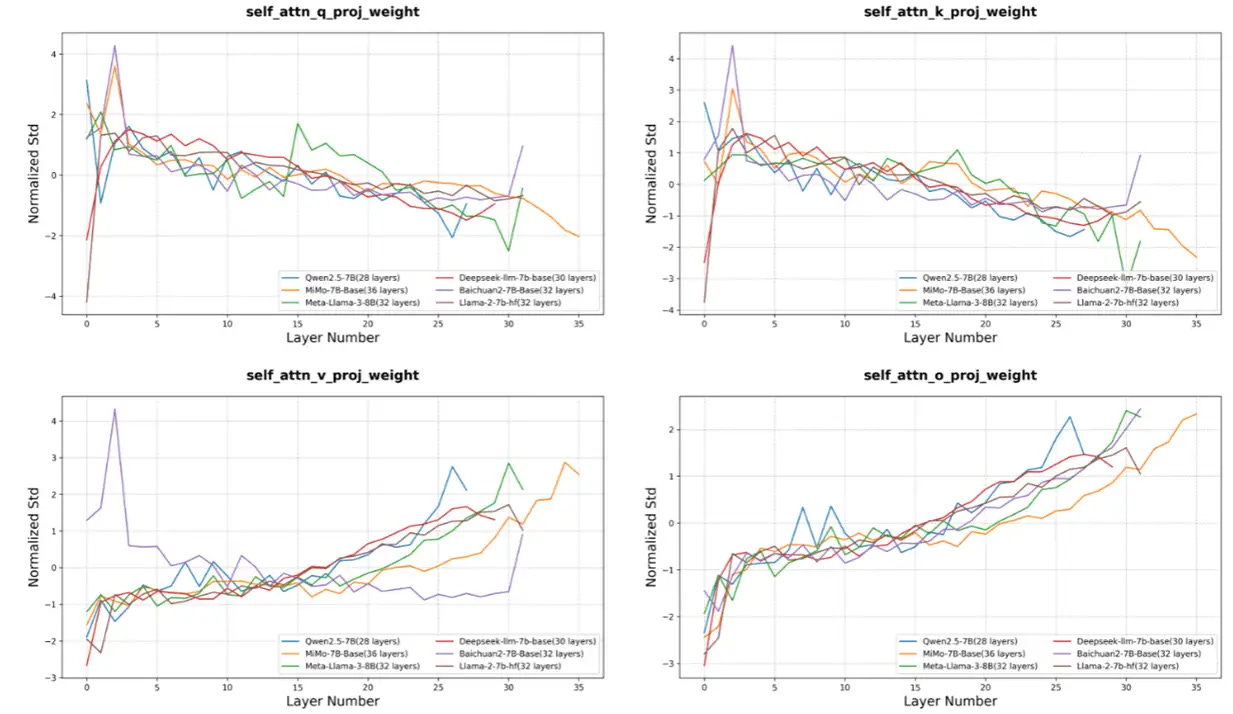
It can be seen that the STD similarity between the different models shows indistinguishable STD on the QKVO weight, so this method is definitely untenable. Voiceover: It is also recommended to test the QKV bias and test it on a larger model according to the original post to verify it thoroughly. However, there are too few models with qkv bias, only qwen models and mimo have qkv bias, and because the data used by qwen models is similar, it is difficult to say that the bias std is similar even if it is measured. Wait a minute, I'll try Qwen and Mimo myself.
2025-07-04 20:33 Update: The original Github link has disappeared for 1 hour, I asked a question at that time, the author replied, and it was 404 after about 3 minutes

The following is https:// github.com/HonestAGI/LLM-Fingerprint Question PanGu-Pro-MoE A README Chinese translation similar to Qwen2.5-14B parameter statistic, used DeepSeek-R1, only the missing link will be made by copying and pasting directly, and no modification has been made. My personal position is that I hope to see a model that is independent from computing resources to training and can benchmark against Gemini, but I firmly oppose academic misconduct such as falsehood and fraud, so I also hope to clarify it as soon as possible:
The Intrinsic Fingerprint of Large Language Models (LLMs): Everything You Need to Continuously Train ≠ Steal Models!
The core problem is that
large language models (LLMs) face serious copyright and intellectual property theft as training costs soar and model reuse becomes commonplace. Traditional watermarking methods are susceptible to continuous training attacks – malicious actors only need further training to erase watermarks!
Key Innovation
The researchers discovered a simple yet ingenious approach: to analyze the standard deviation patterns of attention parameters at each layer of the model. These patterns are like unique "fingerprints" with the following characteristics:
✅ Robustness - withstands a lot of continuous training
✅ Intrinsic - naturally generated
✅ by the model architecture Simplicity - just calculate the standard deviation with torch.std() on the parameter matrix!
MethodologyFor
each Transformer layer, they extract the Q, K, V, O projection matrix and calculate:
σ = std(Matrix_parameters)
and then normalize between the layers to create unique feature signatures that can identify their lineage even after significant modifications to the model.
Explosive discovery
: Huawei's Pangu Pro MoE model showed an extremely high correlation (0.927) with Qwen-2.5 14B, suggesting that it was most likely "upcycling" rather than training from scratch!
This suggests:
potential copyright infringement and fabrication
of information in
technical reports about huge training investments with false claims
Verification results
The method successfully detected known lineage relationships:
✅ Llama-3.1-Nemotron (fine-tuned based on Llama-3.1-70B)
✅ Derivative model
✅ of multiple Qwens Qwen1.5-MoE (upgraded from Qwen-1.8B)
Impact & Significance
️ Protecting intellectual property in the AI industry Detecting model plagiarism
⚖️ with high confidence Providing legal evidence for copyright enforcement
Promoting transparency and accountability in AI development
⚠️ Limitations
Works best on large models (billions of parameters).
It may be less effective on smaller models due to limited statistical power
Need access to model parameters (not just outputs)
Broader Context
This study highlights the urgent need for robust authentication methods because:
Training costs run into millions of dollars
♂️ Competitive market pressures drive rapid growth
Geopolitical Tensions Affect AI Supply Chain
Companies may take shortcuts to demonstrate capabilities
Why it matters
In an era of "continuous training ≠ stealing everything a model needs," this work provides the AI community with practical tools to maintain fair competition, protect innovation, and promote continued technological advancement!
Update
Based on feedback and suggestions from the open source LLM community, we've further examined more architectural patterns for Pangu and other models. The survey focused on QKV bias projections and attention layer normalized weights (attention layer normalization weights), using the same normalized standard deviation measure described in our paper.
QKV bias analysis results
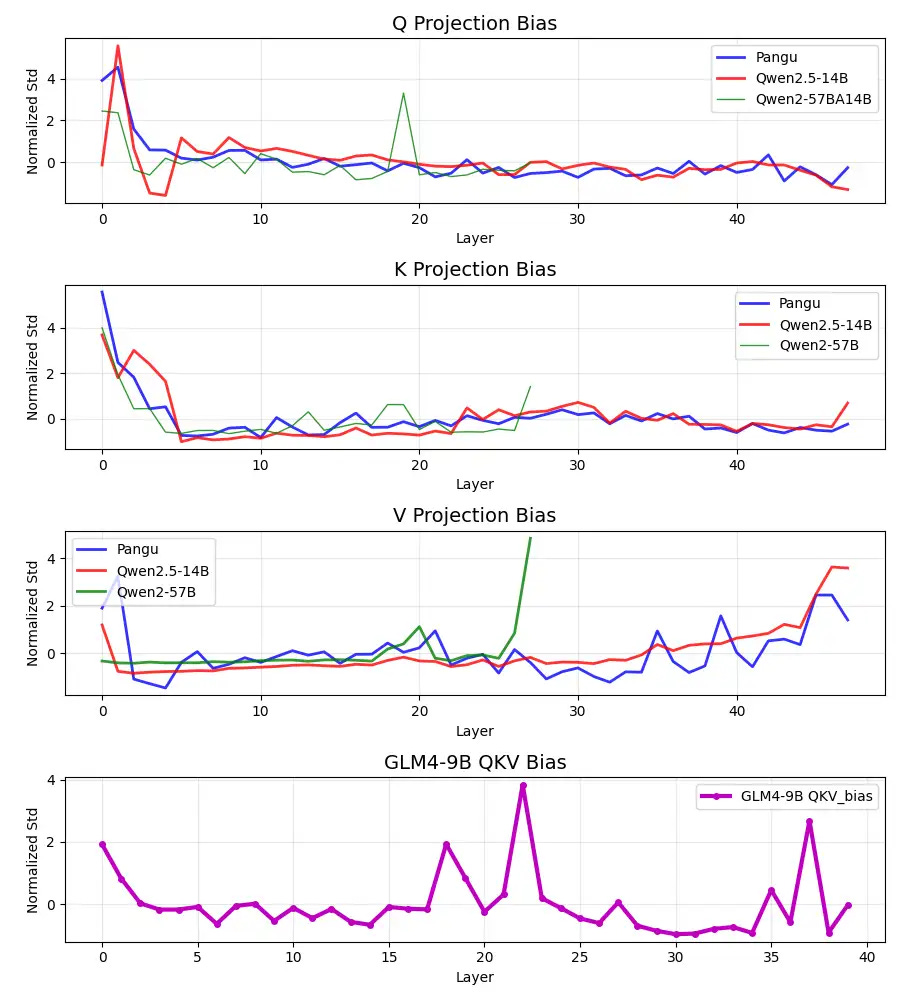
QKV bias analysis revealed striking similarities between Pangea and Qwen2.5-14B across all three projection types (Q, K, V). Both models exhibit almost identical patterns, particularly in the spike characteristics specific to the early layers and the subsequent convergence behavior. This is especially important because QKV bias is a unique design feature of Qwen Gen 1-2.5 models (as stated in their technical report: https:// arxiv.org/abs/2309.16609), which has been abandoned by most open source models, including Qwen3.
Reference Links:
Attention Layer Normalization (LayerNorm) weighting mode
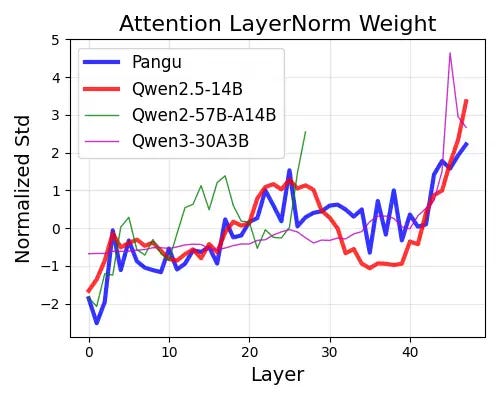
Attention layer normalized weight analysis further reinforces these similarities. Pangu and Qwen2.5-14B show a very consistent trend on the layer sequence, with parallel initialization patterns and convergence behaviors, which distinguish them from other models such as Qwen2-57B-A14B and Qwen3-30A3B.
Beyond Parameters: Model Activation Analysis (Ongoing)
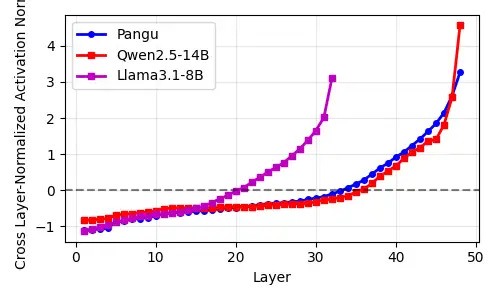
We are analyzing the activation norms for each layer. We're in The Pile A 1k batch of samples was randomly selected on the test set (https:// pile.eleuther.ai/) and the activated paradigm was calculated. We also used a hierarchical normalization approach. The batch size is 8 and the sequence length is 1024. Preliminary results are published here. Pangu is still similar to Qwen. This suggests that there is a significant overlap in their computational models. <br/>Note: For pre-norm-based LLMs, it is common for the activation norm to increase with the number of layers due to residual connections.
The deeper meaning is that
these architectural similarities go beyond coincidental design choices. The observed consistency is almost ubiquitous: QKVO matrix (Figure 3 in our paper), FFN (Figure 8 in our paper), QKV bias, and attention RMSNorm. These are all key components of large language models.
Are all these points a coincidence? I'm afraid not.
One or two types of overlap may be coincidental (see also Figure 3 of our paper, some models may have overlap on the V and O matrices). But in the case of Pangu, there are too many coincidences, and we are investigating more "coincidences" with the open source community. <br/> please don't fool the global community.
Researchers in the LLM community are invited to contribute additional evidence to this case.
Other findings
We also note that Pangea's official repository unusually contains a license for Qwen 2024:
https://gitcode.com/ascend-tribe/pangu-pro-moe-model/blob/main/Open%20Source%20Software%20Notice
https://gitcode.com/ascend-tribe/pangu-pro-moe-model/blob/main/configuration_pangu_moe.py#L3
https:// gitcode.com/ascend-tribe/pangu-pro-moe-model/blob/main/modeling_pangu_moe.py#L3
due to Qwen 2.5 The series was released in 2024, which is consistent with our findings.
We note that the fraud revealed in the repository issue (#2, #4) is also consistent with our findings:
They mentioned that the development team had changed the vocabulary of the model. This may explain why Pangu and Qwen have different word sizes (and the tokens they use). Developers may want to cover up fraud with this deliberate action, as using the same vocabulary makes it too easy for the community to identify the overlap.
Benchmarking cheats by training on a test set are also mentioned in the issue, but this is outside the scope of this project.
We've heard from multiple whistleblowers claiming to be from their team:
They confirmed the allegations against Pangu Pro MoE.
They also confirmed the existence of a version of Pangu Ultra MoE that is "very similar" to DeepSeek-V3 (still an upgrade, but in a different way, which is consistent with the information provided in Issue 2&4).
However, these messages cannot be verified, as the Pangu Ultra MoE has not yet been released, and we are unable to confirm the identities of these whistleblowers.
Executed by the Honest AGI community - Promote transparency and integrity in AI development
Post the hotly debated issue8 https:// github.com/HonestAGI/LLM-Fingerprint/issues/8
The lead developer of 4n0nym0u5-end
Pangu LLM has internally clarified that your evaluation method is extremely unscientific, as follows:
Using the methodology described in your paper, the following model comparisons were evaluated:
pangu-72b-a16b vs QWEN2.5-14b = 0.92
baichuan2-13b vs QWEN1.5-14b = 0.87
baichuan2-13b vs pangu-72b-a16b = 0.84
baichuan2-13b vs QWEN2.5-14b = 0.86
Models with different layers also produced highly similar results under your evaluation methods. This shows that your paper and metrics lack practical significance, and that Pangu does not involve plagiarism.
HonestAGI
thanks for your response. However, we are not convinced for the following reasons:
Pangu still shows the highest degree of similarity, right? We're glad to see that you've managed to replicate our results! Indeed, any classification problem requires a threshold to determine the decision boundary (e.g., in this case, the suspect value is 0.9). This was primarily a tool for initial comparisons, and Pangu "unfortunately" triggered this warning sign before we could begin further investigation.
We don't make judgments based solely on attention parameters. It's just motivation. After our more in-depth investigation (see the analysis of FFN in the paper and the many new results published on the homepage, how do you interpret these?). Are these all "coincidences"? The open-source community is discovering more "coincidences", such as analyzing gradients and KV cache similarities. Please be patient.
Is the qratosone
Qwen2-MoE upcycled from a smaller, denser model?
HonestAGI
Is Qwen2-MoE an upcycling of a smaller, denser model?
Precisely. This fact is mentioned in Qwen 2's technical report https:// arxiv.org/pdf/2407.10671 (see Section 2.2.2).
qratosone
Is Qwen2-MoE an upcycling of a smaller, denser model?
Precisely. This fact is mentioned in Qwen 2's technical report https:// arxiv.org/pdf/2407.10671 (see Section 2.2.2).
In the technical report, the Qwen2-57B-MoE is an upgrade from the Qwen2-7B, so why don't you test the similarity between the Qwen2-57B-MoE and the Qwen2-7B?
HonestAGI
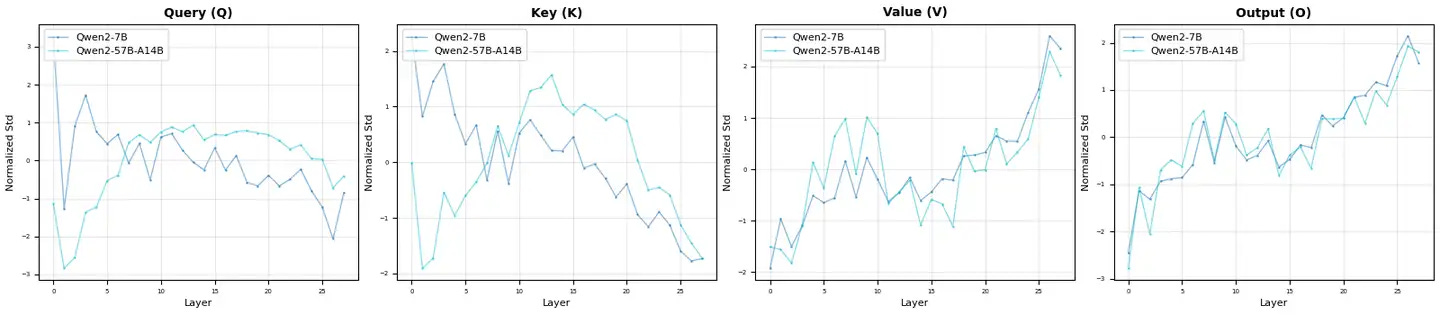
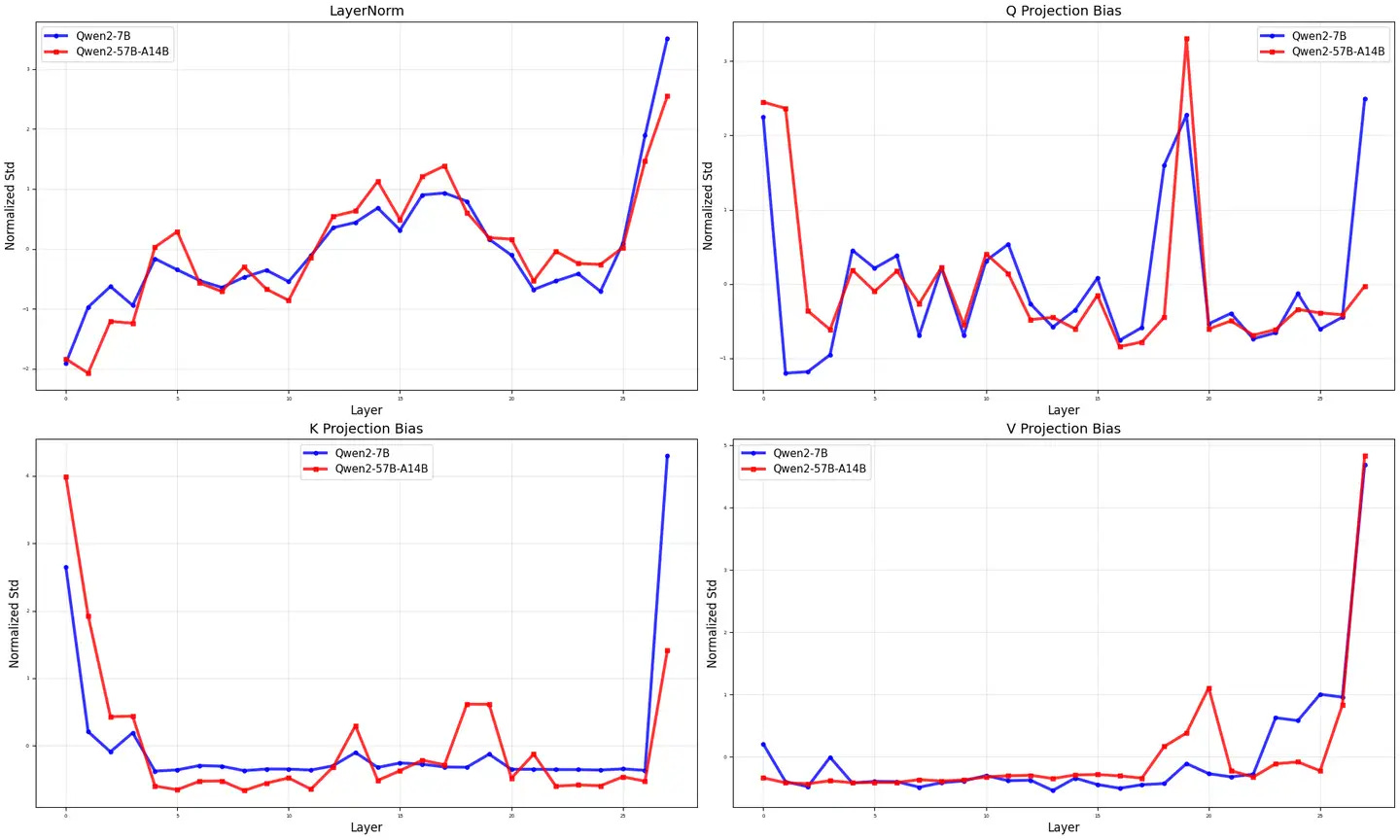
More experiments are currently underway. Excited to share our results:
Based on the experimental analysis of two Qwen models (Qwen2-7B and Qwen2-57B-A14B), the results show significant architectural similarity between the two variants, highlighting the effectiveness of the Qwen complex upgrade method.
The high degree of model similarity
comparison reveals a striking consistency between most of the architectural components. The LayerNorm mode shows nearly the same trajectory in all layers, and both models follow the same normalized standard deviation pattern. This consistency extends to the value (V) projection and output (O) projection components, where the two models exhibit almost exactly overlapping behavior on all layers.
Most notably, the query (Q) bias term also exhibits a high degree of similarity between the models, following comparable trends and amplitudes across the network depth. This consistency across multiple key components shows that the basic architectural principles and learned representations are well preserved as the model scales.
The main difference between the strategic difference
models for key components appears to be particularly evident in the key (K) projection bias term, which shows a more significant change compared to the more stable mode in Qwen2-7B. This targeted difference suggests that Qwen's upgrade process selectively modifies the key attention mechanism while maintaining the integrity of the other components.
All in all, by combining the analysis from different perspectives, the "fingerprint" recognition of the model is more accurate. In the case of the Qwen2 MoE model, it is not so similar to its core 7B model in various ways. Unfortunately, the Pangu model is too similar to Qwen in too many ways.
qratosone
... (citation omitted)
So, based on the method you mentioned in Figure 3, what are the correlation profiling results between Qwen2-57B and Qwen2-7B, and between Qwen1.5-MoE and Qwen-1.8B?
HonestAGI
... So you mean, your Figure 3 is the result of carefully selected data?
These results have just been obtained. We were absolutely not hand-picked when we did the initial analysis (because we hadn't done the experiment yet). In fact, we plan to update our paper once we have gathered enough community feedback. Thank you for your constructive suggestion to supplement the results of this experiment, which further reinforces our key conclusions.
qratosone
... (citation omitted)
In my opinion, in order to prove your conclusions, it is necessary and valid to make a direct comparison of the same set of accepted upgrade models, including Qwen2-57B/7B and Qwen1.5-MoE/1.8B, using the comprehensive correlation analysis method you mentioned in Figure 3. There is no need to compare Qwen2-57B and Qwen1.5-MoE with other models, you just need to compare them with their original dense models. In order to prove similarity, it is necessary to conduct a correlation analysis rather than just a projection of the showcase.
qratosone
In addition, you claim that "Qwen's upgrade process selectively modifies the key attention mechanism while maintaining the integrity of the other components". Can you cite a technical report to support this statement?
qratosone
In addition, given that this experiment is not expected to be particularly GPU intensive, I think open-sourcing your code implementation will help facilitate community contributions and collaborative experimentation.
HonestAGI
good advice. This will really improve the way the experiment is organized. We plan to submit the paper to a peer review conference (maybe ICLR or later?) once it has been completed (with all the code deposited?). )。
For your other question: Qwen2 uses a noisy upcycling approach to introduce diversity to experts. Our guess is that this operation might alter the activation of Q and K (since QK norm is not applied here), resulting in a shift in the parameter distribution. This is quite interesting and we think further research can be done on this topic. This may be useful in understanding the training dynamics of MoE (even those MoE models that are trained from scratch).
There
are also rumours that the Mistral-7B was developed based on a certain version of the Llama family.
And, to make the conclusions more credible, I suggest adding more experiments on the open-source model.
The current results are still not convincing enough:
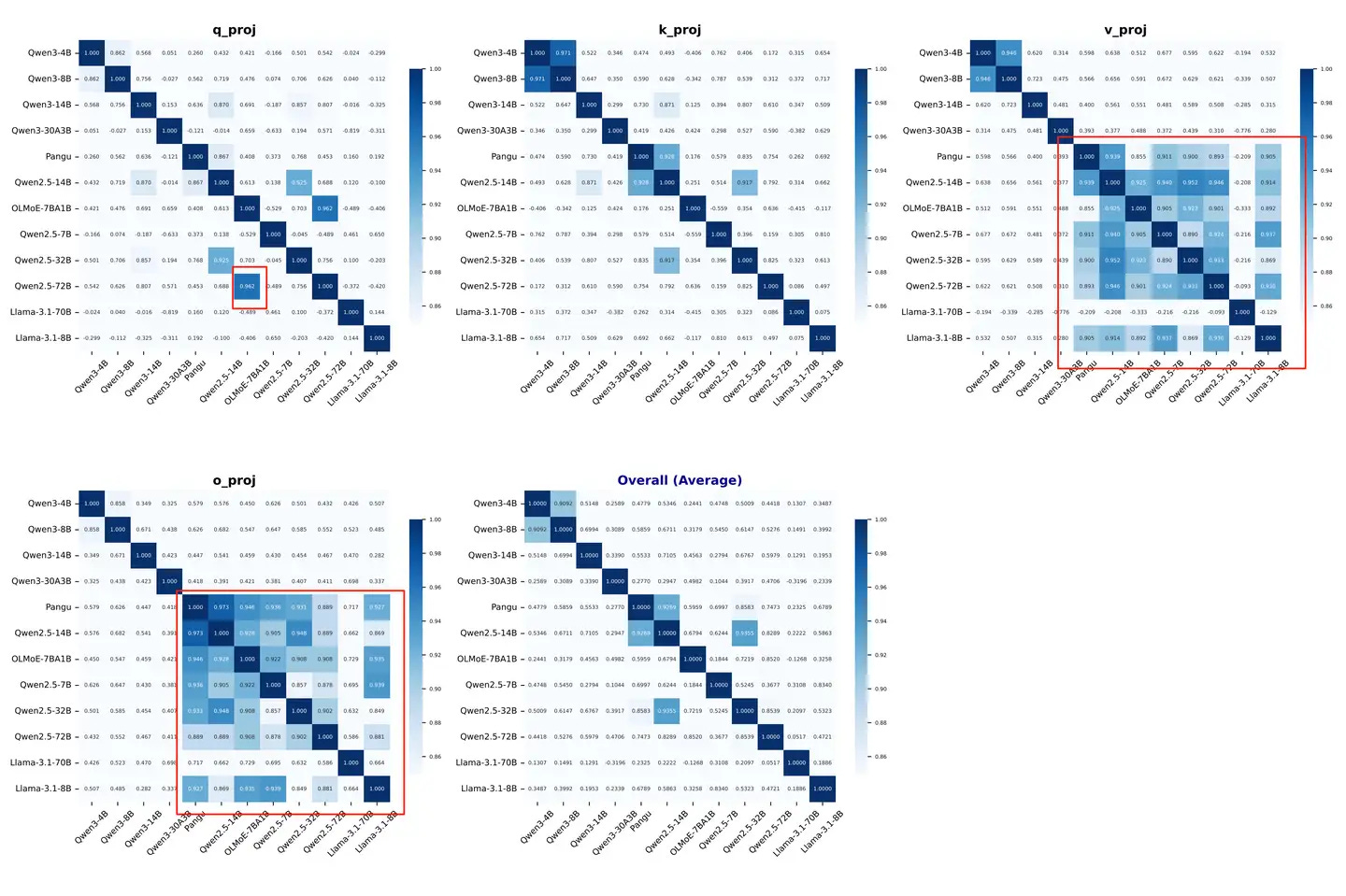
HonestAGI
There are also rumours that the Mistral-7B was developed based on a certain version of the Llama family. And, to make the conclusions more credible, I suggest adding more experiments on the open-source model. The current results are still not convincing enough:
pictures
Interesting. We weren't aware of this rumour before. Let's try to verify it. The results will be announced soon in this thread.
Linkedlist771 found and discussed
fingerprints to determine if Pangu is cheating. I've also found some papers that are also looking at this issue:
https://arxiv.org/html/2502.00706v1
https://arxiv.org/html/2506.01631v1
You can refer to their analysis methodology, especially the section on confidence levels, to verify your analysis results.
HonestAGI
By the way, we provide here a comparative analysis of Qwen vs Hunyuan A13B, which was mentioned in the following tweet: https:// x.com/teortaxesTex/status/1940951778234974325
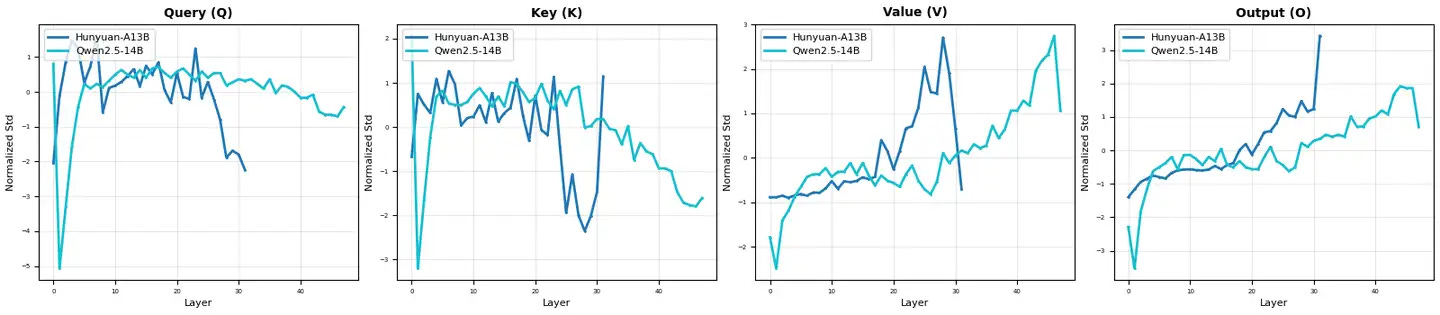
Based on these visualizations, the hybrid-Hunyuan-A13B and Qwen2.5-14B exhibit very different internal patterns at different levels, suggesting that they have quite different architectures and learned representations. This diversity of models is actually a good thing for the AI field – it shows that teams are exploring different ways to innovate, rather than just imitating each other!
(Note: Due to the rapid increase in replies to this Github issue, the next few uninformative posts will not be translated)
tycheung625
By the way, we have provided here a comparative analysis of Qwen vs Hunyuan A13B, which was mentioned in the following tweet: https:// x.com/teortaxesTex/status/1940951778234974325
Based on these visualizations, the hybrid-Hunyuan-A13B and Qwen2.5-14B exhibit very different internal patterns at different levels, suggesting that they have quite different architectures and learned representations. This diversity of models is actually a good thing for the AI field – it shows that teams are exploring different ways to innovate, rather than just imitating each other!
So, can your work specify where exactly Pangu copied Qwen 2.5 and pinpoint exactly where these plagiarism occurred? I think that would be more effective. My intent is to expose this problem at the model level.
qratosone
Includes Qwen2-57B/7B and Qwen1.5-MoE/1.8B. There is no need to compare Qwen2-57B and Qwen1.5-MoE with other models, you just need to compare them with their original dense models. In order to prove similarity, it is necessary to conduct a correlation analysis rather than just a projection of the showcase.
Is there an update on the correlation analysis between Qwen2-57B/7B and Qwen 1.5-Moe/1.8B?
guoqiangqi (deleted post)
It's really inspiring to witness such a high level of professional discussion in the open source community. I'm not an expert in the field, but I've been poring over the various points of view that have been made. I have a few thoughts on this issue:
Logically, the new approach you proposed does provide an innovative perspective for model similarity assessment. However, have we given sufficient consideration: does the proven high similarity necessarily mean plagiarism? There may be other underlying mechanisms or confounding factors that contribute to similar results.
While the method has been validated on existing benchmark models, how can we ensure that its evaluation of new open source models is reliable? In particular, I would like to know how well the scoring system generalizes across different model categories and architectures.
HonestAGI
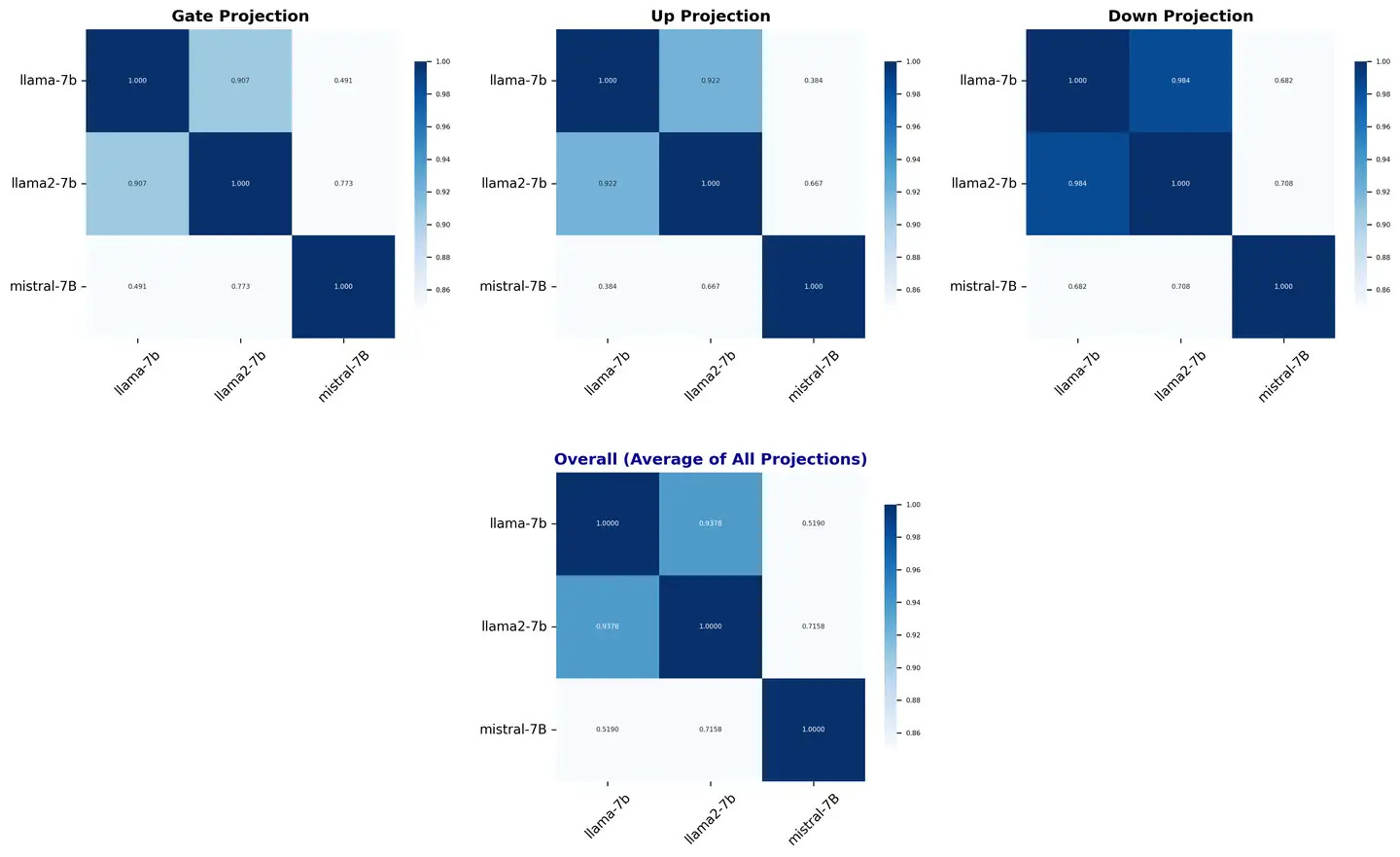
Based on the latest experimental results, we can perform deep similarity analysis on three other old models:
The similarity matrix of Llama-7b and Llama2-7b similarity analysis
shows that there is a significant correlation between the two in multiple dimensions:
Attention mechanism:
The similarity of Q and K projection matrices is low, while the similarity of V and O matrices is highFFN parameter similarity:
The similarity of Gate, Up, and Down projection all exceeded 0.9. This high similarity may be due to:
✅ Reuse of training data: Llama2 is likely to use a large amount of pre-training data
✅ from Llama1 Hyperparameter configuration: Key hyperparameters such as learning rate and optimizer settings are highly similar
Verification of the independence of the Mistral-7B compared with the Llama series of models shows that:
The similarity between the Mistral-7B and the Llama series is significantly low, both in terms of FFN and attention parameters
There is no sufficient evidence that Mistral-7B originated in Llama or that there is a significant reference to it
tycheung625
... (citation omitted)
Is there an update on the correlation analysis between Qwen2-57B/7B and Qwen 1.5-MoE/1.8B?
That's the problem, buddy
HonestAGI
We have completed a number of complementary results for correlation analysis between Qwen2-57B/7B and Qwen 1.5-MoE/1.8B.

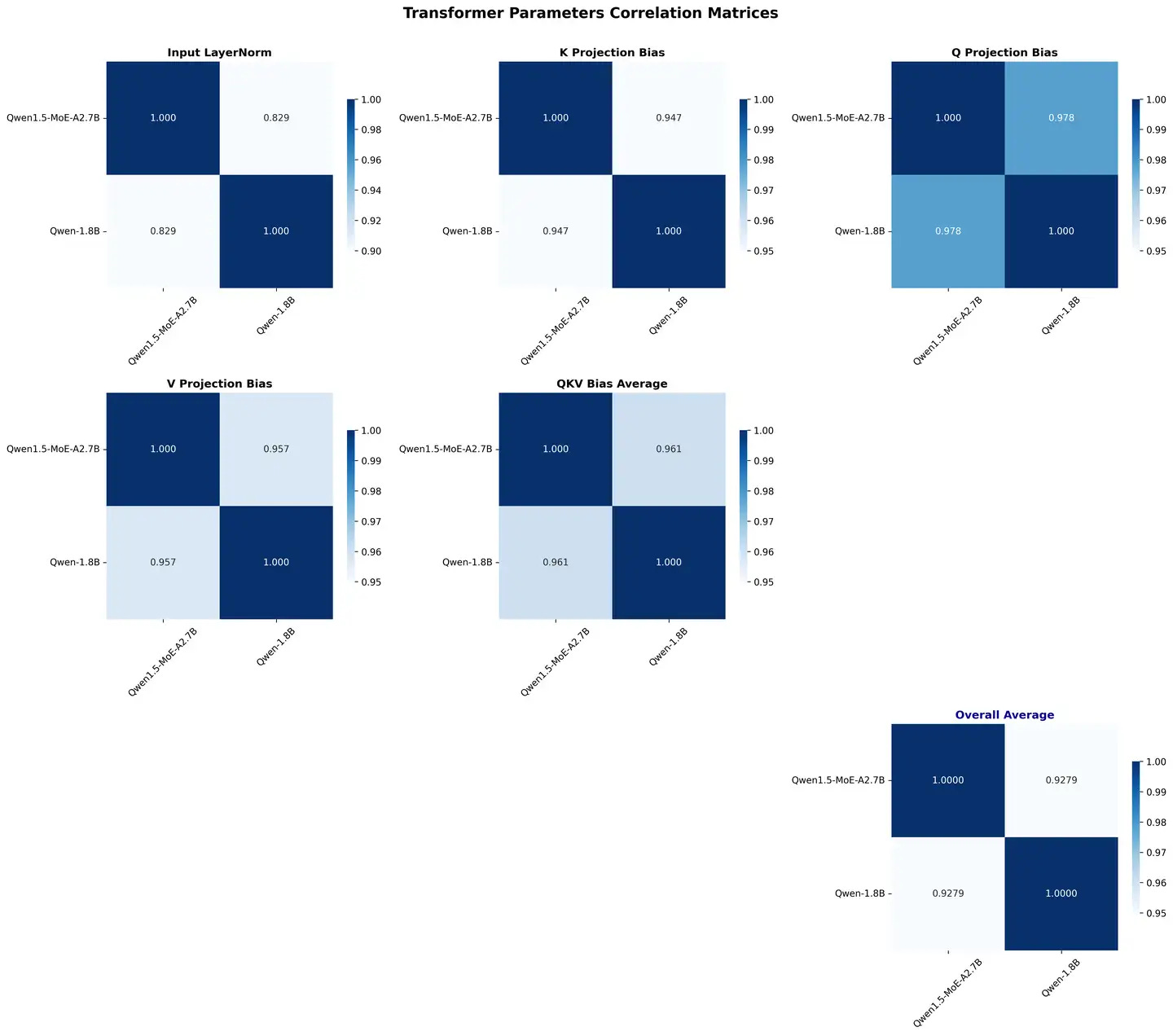
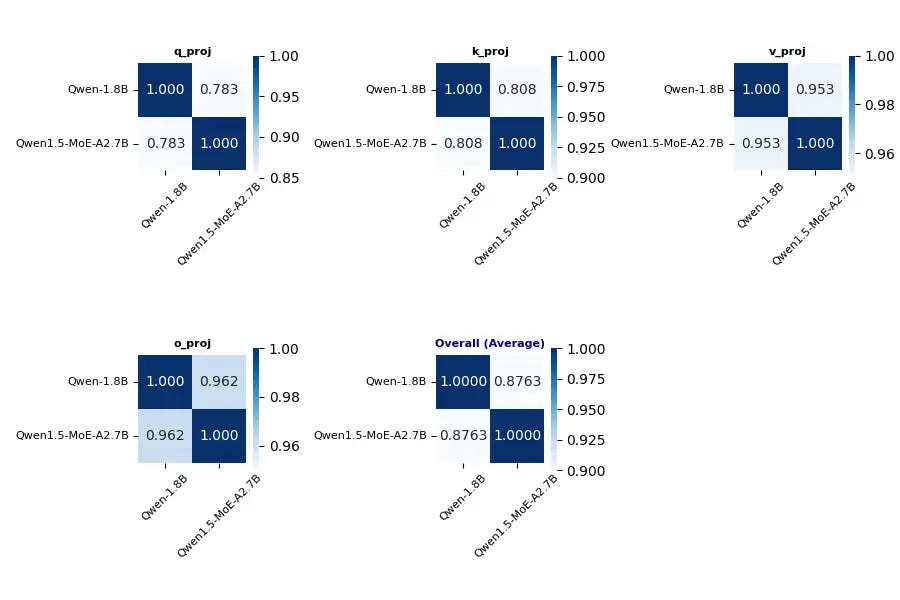
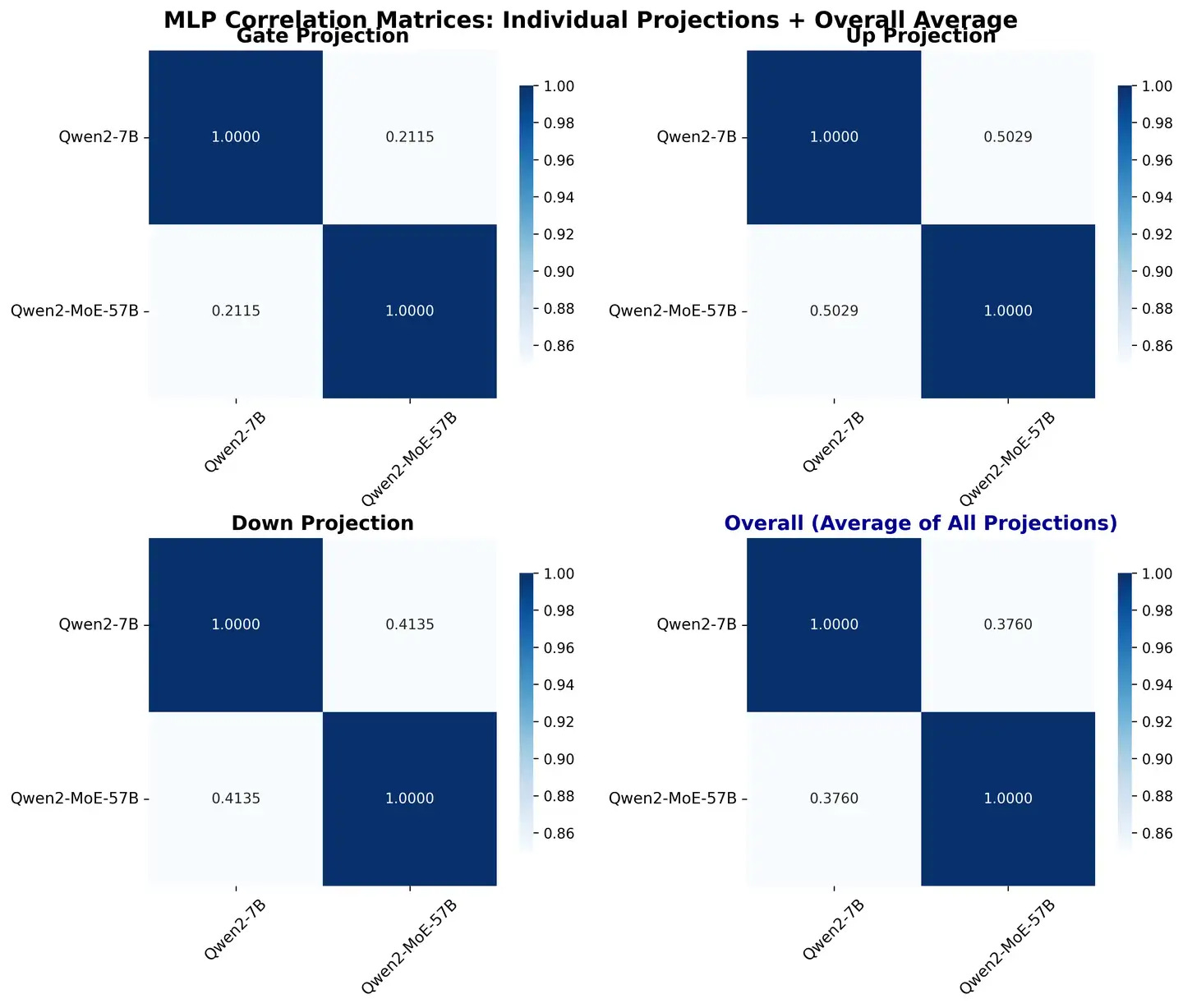
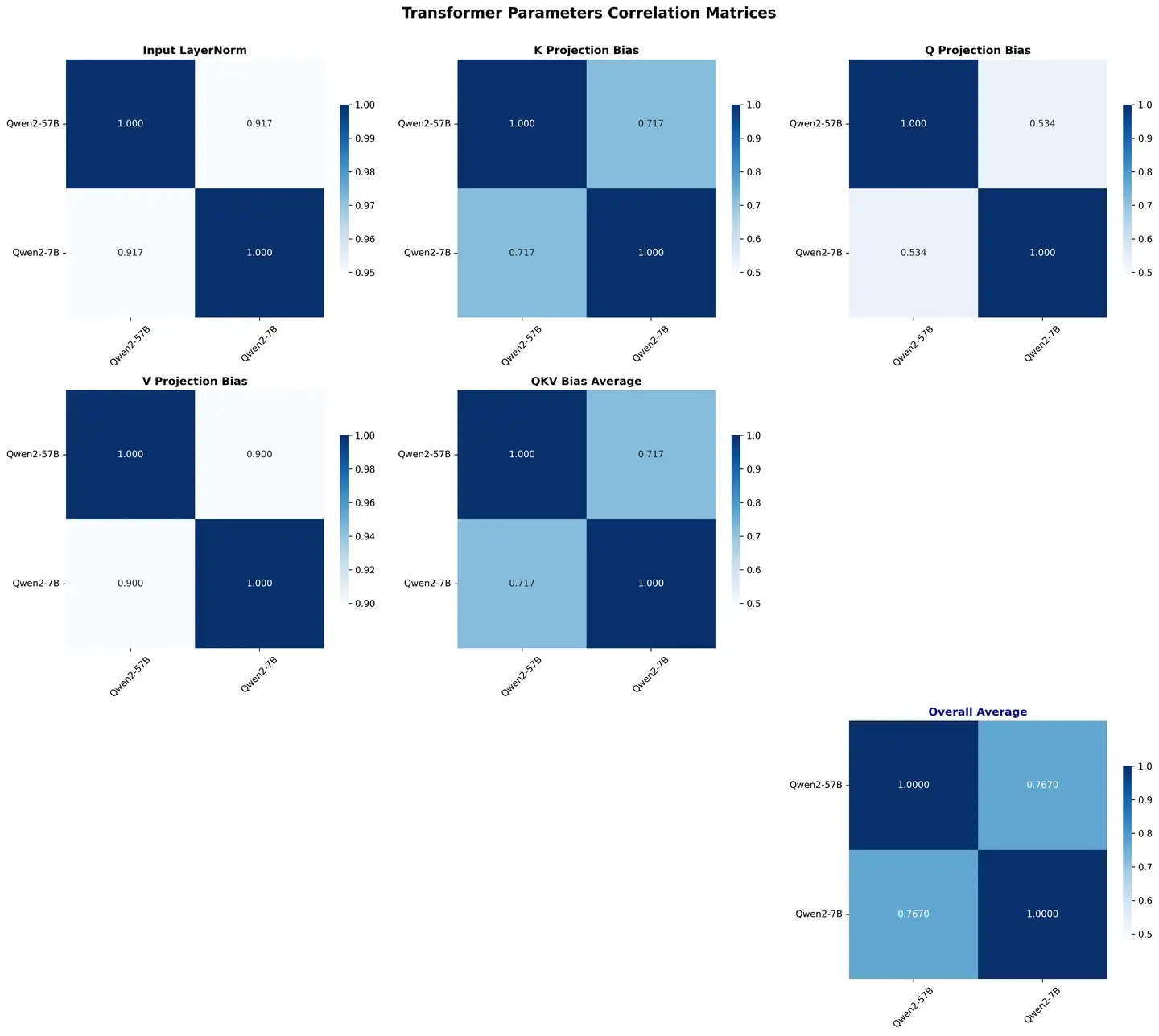
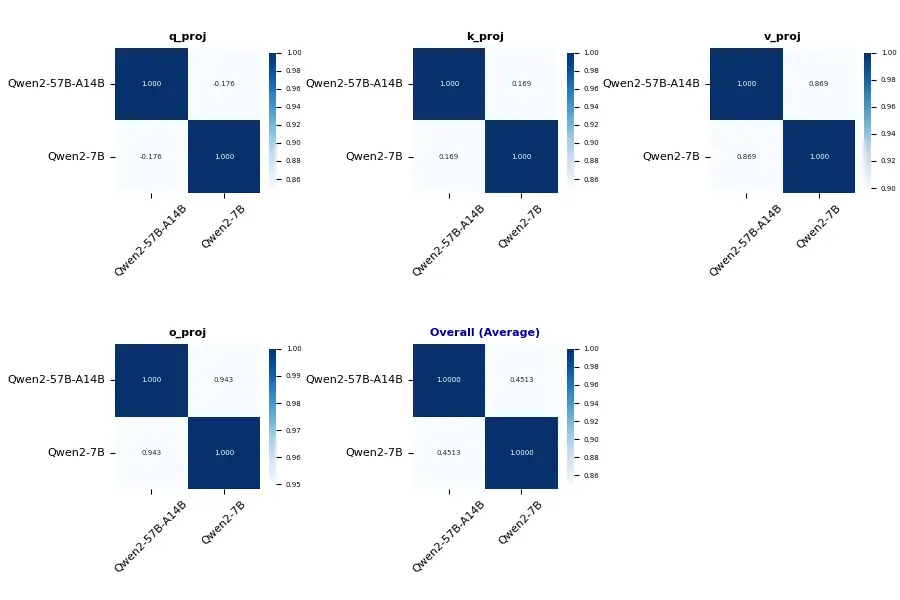
We can see:
FFNs are not very similar and may be due to the operations used in upcycling.
For the Qwen series, QKV's bias seems to be a very good sign.
In Qwen 1.5, the similarity of QKVO is high; But in Qwen 2, only V and O show similarity.
The overall similarity of upcycling on Qwen2 is lower than that of Qwen 1.5, probably due to longer training and the use of more advanced upcycling techniques.
chenjoya (here I asked myself because I felt that the evidence he gave on QKV bias was obviously insufficient)
… (citation omitted)
Can you share more about the analysis of QKV bias between models? I'm concerned that a lot of model families — not from upcycling, but similar in architecture — might also exhibit the similar bias pattern you show.
HonestAGI
Can you share more about the analysis of QKV bias between models? I'm concerned that a lot of model families — not from upcycling, but similar in architecture — might also exhibit the similar bias pattern you show.
Of course. Most models with independent QKV bias belong to the Qwen family. We are looking into this further.
HonestAGI exposed
作者:知乎用户
链接:https://www.zhihu.com/question/1924254207063593527/answer/1924471303143929733
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
He proposed this relevance evaluation index himself, and the paper can be found in his own repository https:// github.com/HonestAGI/LLM-Fingerprint
Let the bullets fly for a while, it's too exciting, I have looked at the paper at present, there is some truth, but the experiment is still not sufficient, the most critical point is that it did not indicate which module was plagiarized, and besides, it is doubtful to only look at whether the parameter weights can determine plagiarism. Has anyone analyzed the source code of the Pangu model, I think the source code of the model is the only standard.
But there is one point, this team is so fast, it is a little doubtful whether it wants to take advantage of Huawei's hot spot
Update:
Here's another research effort on the correlation of large models:
https:// arxiv.org/pdf/2502.00706v1
https://arxiv.org/html/2506.01631v1
Update:
Well, after reading the latest reply, I kept putting the line chart, there is no correlation real value, and the results of the most critical qwen and qwen moe are not given, whether I haven't finished running or don't want to give. The paper says correlation analysis, which is a bit contradictory
Last updated:
Solve the case, the papers are all written by AI, the authors are all pseudo-people, they can't be found at all, they are students, there is no edu mailbox, there are several paper references that are fake, and the reality does not exist at all, what does this mean, I think a graduate student knows it, at present, the so-called team has deleted the library and run away, of course, you can also say that Huawei has made efforts, but github China has no agent, and the maintenance is abroad.
The discussion revolves around allegations of plagiarism and academic misconduct related to the Pangu model developed by Huawei. Here's a detailed summary of the key points and developments:
Latest Update:
Huawei Pangu and Qwen 2.5: Similarities and differences between QKV bias (Alibaba Employee on Qwen)
Recently, Huawei announced that it has open-sourced its first hybrid expert (MoE) model -pangu-pro-moe。 The release itself didn't spark much of a heated discussion in the community, but the "parameter fingerprinting" analysis initiated by HonestAGI unexpectedly sparked a broader discussion. HonestAGI was compared by pangu-pro-moe with Qwen 2.5-14BQKV projection biasand attention layer normalized weights"Normalized standard deviationcurves, and found that the two showed a high degree of similarity, and therefore speculated that Pangu may have a deep correlation with Qwen2.5. HonestAGI's analysis focused on QKV bias andLayerNorm weightThe Normalized Standard Deviation curve. This metric measures the degree of dispersion of values in a parameter tensor and is normalized to some extent. The HonestAGI chart shows that these "normalized standard deviation" curves of Pangu and Qwen2.5-14B are highly consistent in terms of the wave patterns between layers, which does constitute a strong evidence that the two may have similarities in architectural design, training paradigms, and even some deep optimization strategy, or share a common "ancestor model".

From the perspective of device-side inference, Qwen's QK evolution is seen56 Endorsements · 2 Commentsessay
It just so happens that I just wrote about the research on the characteristics of the Qwen series of models QK some time ago, and I would like to take this opportunity to compare the similarities and differences between these two models. I still chose the previous entry point, the Max Bias Value of the QKV projection offset. Because the Qwen 2.5 series model has a very big feature, that is, the maximum bias of QKV proj is very large, which I also found when I used fp16 overflow in device-side deployment, which was introduced in the above article. I think this indicator has a more intuitive reference value for judging whether the model directly "reuses" the pre-trained weights of another model. If a model is initialized directly based on the weights of another model, its initial parameters, including biases, should be highly consistent with the source model. Then, if the Pangu model uses the parameters of Qwen2.5 as the initialization weight, it is likely to retain the characteristics of QKV-Bias.
Qwen7B series
First of all, I made a statistic on the Qwen 2.5-7B series models (because I have limited computer space, I mainly store models that are less than or equal to 7B suitable for the device side, so I chose the 7B series for observation). As shown in the figure below:
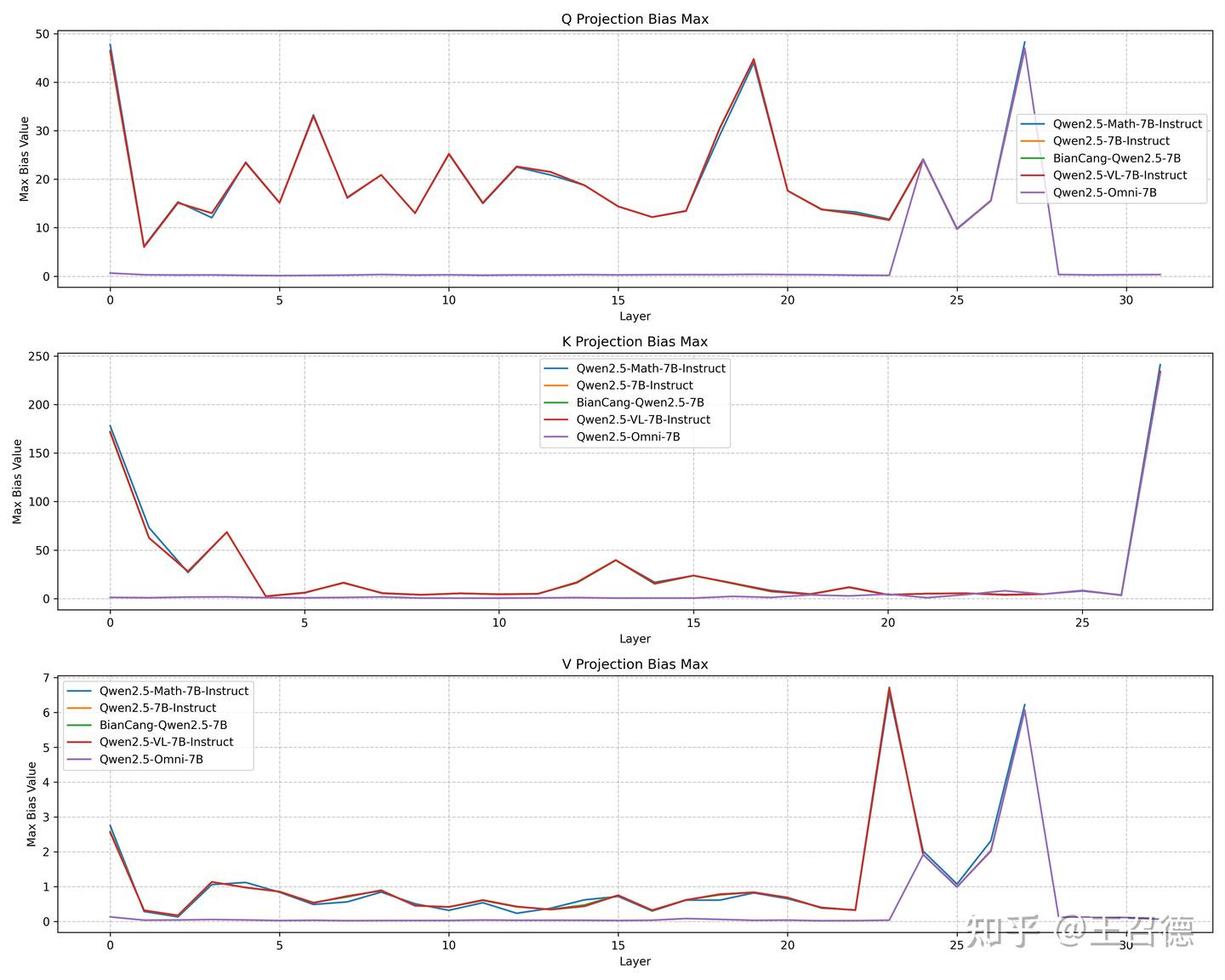
From this graph, we can clearly see that despite being different 7B variants, their hierarchical distribution curves at Q, K, and V offset maxima show a highly similar pattern, with close overlap with each other. Even though the initial layer of the Omni model changes a bit bit, the tail is still largely overlapped. BianCang is a domain model of TCM, which is basically the same as the original model.
Pangu and Qwen14B
Next, we turn our attention to the comparison of the pangu-pro-moe model with the QKV bias maximum of Qwen2.5-14B-Instruct. As shown in the figure below:

The results are very different:
The maximum QKV bias of Qwen2.5-14B-Instruct (green line) shows obvious and complex fluctuations between different layers, especially in Q and K biases, the peak value can reach 10-20 or even higher, and the V bias also has significant values in some layers. Qwen2.5-14B-DeepSeek-R1-1M is based on the fine-tuned version of Qwen2.5-14B-Instruct, which is exactly the same as Qwen2.5-14B-Instruct.
The maximum QKV bias of the pangu-pro-moe (blue line) is almost flat close to the 0 axis! This means that the absolute value of its QKV bias is always very close to zero.
This significant difference, for me, is as follows:
Characteristics of QKV bias: QKV bias is an important parameter in the attention mechanism, and they are carefully adjusted during the model learning process to optimize the computation of attention and information aggregation. If a model's biases have learned large non-zero values, they reflect the model's encoding of some inherent "tendency" of the data.
Training difficulty analysis: If PanGu-Pro-MoE is directly initialized and subsequently trained based on the weights of Qwen2.5-14B, then the initial state of its QKV bias should be highly similar to that of Qwen2.5-14B (i.e., it has a large fluctuation value). It is very difficult and uncommon to train these learned, large bias values to such close to zero in subsequent training. Typically, training (including fine-tuning) adjusts parameters, but rarely zeros them out, unless there is an explicit sparsity or specific regularization goal, or the model itself is initialized from zero with the bias tightly constrained. Given the complexity of training large models, training the entire bias distribution from significantly non-zero to almost zero without affecting model performance is a challenging task in itself.
Combining with HonestAGI's Perspectives: So, does this contradict HonestAGI's observation of "normalized standard deviations"? My point is that this is not a contradiction, but provides a more nuanced perspective. HonestAGI focuses on the similarity of parameter distribution morphology (measured by standard deviation), which may be due to similar architectural designs. The difference in the "offset maximum" I observed points more directly to the source of the initial value of the parameter.
conclusion
According to the distribution of the maximum bias value of the QKV projection, it is likely that the pre-trained weight of Qwen2.5-14B is not directly used as the initialization parameter of the pangu-pro-moe model. There is an essential difference in the absolute numerical distribution of the bias, and it is difficult to evolve from one model state to another through conventional fine-tuning or continuous pre-training.
This does not preclude that pangu-pro-moe and Qwen 2.5 have a high degree of consistency in architectural design. This similarity in architecture and design concepts may lead to the similarity of the "normalized standard deviation" model observed by HonestAGI, but the structural consistency is not a problem in the large model, because a good structure is the common choice of everyone, and the overall architecture of the large model is converging.
Code & Data
llm-lab/qkv_bias at main · wangzhaode/llm-lab
Original source: Huawei Pangu and Qwen2.5: Similarities and differences between QKV bias - Zhihu
Background and Allegations
Initial Claims by HonestAGI:
HonestAGI alleged that Huawei's Pangu Pro MoE model showed an extremely high correlation (0.927) with Qwen-2.5 14B, suggesting potential plagiarism.
They used a method involving the analysis of standard deviation patterns of attention parameters at each layer of the model, which they claim acts as unique "fingerprints."
Methodology:
The method involves extracting the Q, K, V, O projection matrices from each Transformer layer and calculating the standard deviation (σ) of these matrices.
These standard deviations are then normalized to create unique feature signatures that can identify model lineage even after significant modifications.
Responses and Counterarguments
Pangu Team's Response:
The Pangu team responded by stating that the evaluation method used by HonestAGI is unscientific.
They conducted their own evaluations using HonestAGI's method and found high similarities between various models, including those with different layers, which they argue undermines the validity of HonestAGI's claims.
Community and Expert Reactions:
Several community members and experts have weighed in on the discussion, with some supporting HonestAGI's findings and others questioning the methodology and conclusions.
Concerns were raised about the sufficiency of the experiments and the lack of specific evidence pointing to which modules were allegedly plagiarized.
Additional Findings and Updates
QKV Bias Analysis:
HonestAGI provided additional analysis on QKV bias, showing similarities between Pangu and Qwen2.5-14B.
They argued that these similarities go beyond coincidental design choices and suggest a deeper connection between the models.
Whistleblower Claims:
Multiple whistleblowers claiming to be from Huawei's team confirmed the allegations against Pangu Pro MoE.
They also mentioned the existence of a version of Pangu Ultra MoE that is "very similar" to DeepSeek-V3, although these claims could not be verified.
Academic Misconduct and Fabricated References
Fabricated References:
It was discovered that several references cited in HonestAGI's paper do not exist, raising concerns about academic misconduct.
The fabricated references were seen as a serious breach of academic integrity, further complicating the credibility of HonestAGI's claims.
Deletion of Repository:
The original Github repository containing HonestAGI's findings was deleted, adding to the controversy and speculation about the motives behind the allegations.
Conclusion
The discussion highlights the complexities and challenges in determining plagiarism and academic misconduct in the field of AI model development. While HonestAGI's initial claims raised serious concerns, the subsequent responses and counterarguments have cast doubt on the validity and scientific rigor of their methodology. The fabricated references and deletion of the repository have further complicated the issue, underscoring the need for transparency and integrity in academic research.
Final Thoughts
The case serves as a reminder of the importance of thorough and rigorous evaluation methods in academic research. It also highlights the need for open and transparent discussions within the research community to address allegations of misconduct and ensure the integrity of scientific findings.